딥러닝 모델을 사용해 서버 배포하기 첫번째는 어떤 모델을 사용할까에 관한 내용입니다!
이번에 제가 사용해 본 모델은 Saliency map을 딥러닝으로 예측하는 모델입니다.
saliency map 예측 관련 벤치마크를 비교해 놓은 사이트가 있는데,
저는 여기서 python으로 구현된 모델들 중 MSI-Net을 사용했습니다.
이번 포스팅에서는 MSI-Net논문의 내용을 리뷰하면서 어떤 모델인지 살펴보겠습니다.
Contextual Encoder-Decoder Network for Visual Saliency Prediction
Saliency map이란

사람이 어떤 장면을 봤을 때 집중해서 보게되는 부분을 시각화한 것
처음에는 밝기차이, 색상차이 등의 low level feature를 이용했다면, 최근의 연구에서는 CNN등의 모델을 통해 다양한 feature를 이용하고 있음
모델 구조

크게 Encoder, ASPP, Decoder 세 부분으로 나뉨
Encoder : 기본적으로 VGG16 구조를 사용하고, 몇 가지의 수정사항을 추가
-
Dilation Convolution Layer 사용
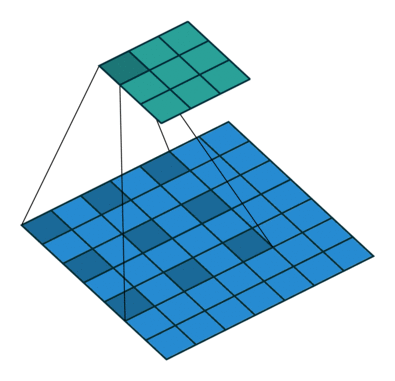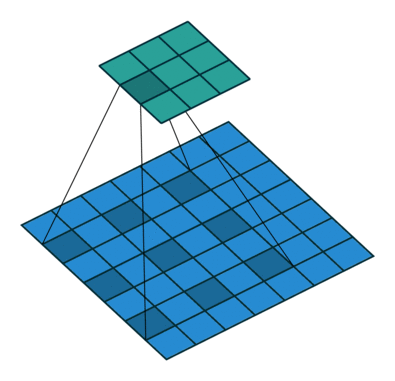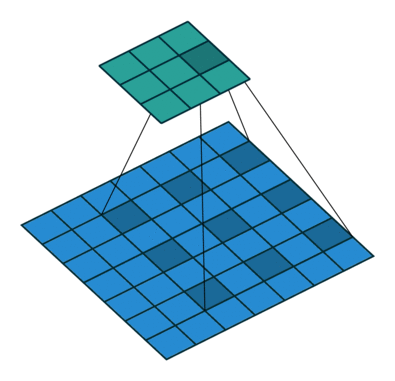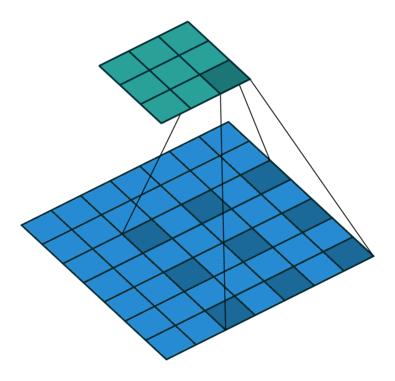
기본 Convolution 연산은 필터크기와 동일한 시야 (receptive field)를 가지는데 비해,
Dilation Convolution 연산은 같은 연산비용 대비 더 넓은 시야를 가짐
- pre-trained 된 VGG16모델을 사용할 때 파라미터 수가 동일하기 때문에 그대로 사용할 수 있음
- 논문에서는 위의 사진과 같이 rate=2 인 필터를 사용했으며, 33 필터이지만 55와 거의 유사한 영역을 봄
선행 연구에서 Saliency Map에는 Dilation Convolution이 좋다고 해서 사용… -
- Pooling layer들을 concat한 값을 최종 결과로 사용
-
각각 다른 level에서의 pooling layer 값들은 공간적 특징을 보존하므로,
w*h 차원이 같은 마지막 세 pooling layer들을 concat해서 공간적 특징을 보존하는 activation map 생성
-
모델 구조에서 첫 번째 pooling layer의 shape는 (?, w, h, 256) 이고,
두 번째와 세 번째 pooling layer의 shape는 (?, w, h, 512) 이므로 axis=3 기준으로 concat했을 때 최종 (?, w, h, 1280) 인 activation map 생성
ASPP
DeepLab V2 (Segmentation 모델) 에서 제안된 방법
갯수는 같고 파라미터 (rate, size, padding)가 다른 여러 필터를 적용한 후 concat 해 사용
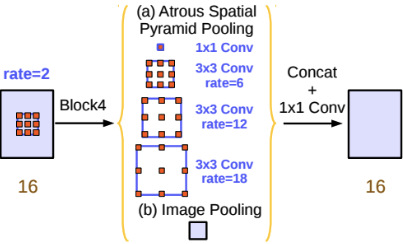
- 논문에서는 총 5개 종류의 필터 종류를 사용
- 각 필터를 거친 결과는 (?, w, h, 256) 이고 5개를 concat 하므로 (?, w, h, 256*5)
- 최종 출력은 (?, w, h, 256) 이어야 하므로 concat 결과에 마지막으로 필터 256개를 사용하는 1*1 convolution 연산을 해줌
Decoder
원본 이미지와 같은 크기의 Saliency map을 생성하기 위해 convolution + upsampling
-
bilinear로 upsampling
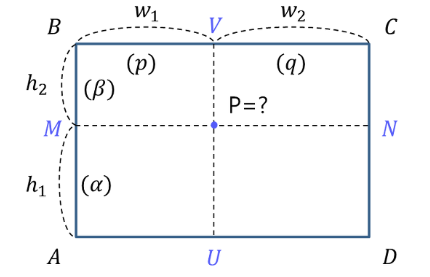
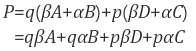
- 앞에서 22 pooling 을 세 번 했으므로 upsampling+convolution도 22 로 세 번 해주면 됨
- upsampling 결과를 128 → 64 → 32 → 1 개의 필터로 convolution 하며 최종 saliency map 생성
학습하기
- Encoder는 ImageNet 과 Places2로 pre-train된 VGG16구조를 사용
- ImageNet : 1000개의 클래스로 구성된 물체 이미지 데이터셋
- https://gist.github.com/aaronpolhamus/964a4411c0906315deb9f4a3723aac57 (클래스목록)
- 이미지 + 이미지의 클래스 정보 로 구성
- Places2 : 400개의 클래스로 구성된 장소 이미지 데이터셋
- https://github.com/metalbubble/places_devkit (클래스목록)
- 이미지 + 이미지의 클래스 정보 로 구성
- ImageNet : 1000개의 클래스로 구성된 물체 이미지 데이터셋
- ASPP와 Decoder weight는 Xavier 초기화를 사용
- https://reniew.github.io/13/ (Xavier 초기화 설명)
- Loss는 KL Divergence 를 사용
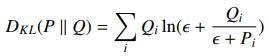
- saliency map 을 분포 예측이라고 생각
- Q는 target 분포, P는 예측 분포, i는 각 픽셀의 인덱스
-
학습 데이터 셋은 세 가지
- MIT1003 : 실내, 실외 풍경 데이터 300개
- CAT2000 : 20개 카테고리 (예술작품, 만화 등 ..) 데이터 4000개
- 이미지 + 이미지의 saliency 정보 (matrix)
- SALICON : COCO 이미지 중 160개 카테고리에 대해
- 이미지 + 이미지의 saliency annotation 정보 (json)
한계점

(a) 어두운 얼굴 (b) 작은 글씨 (c) 사진 내 사람들의 시선 (d) low-level의 대비되는 feature 을 잘 못 찾음